Szybki RAG na AWS: Bedrock Knowledge Bases + S3 Vectors

RAG Chatbot to jedno z typowych zastosowań AI Wykorzystując Amazon Bedrock Knowledge Bases oraz Amazon S3 Vectors, jesteśmy w stanie szybko zbudować system, który wyszukuje kontekst w danych i generuje sensowne odpowiedzi. Choć z zewnątrz wygląda to prosto, stworzenie dobrego RAG-a wymaga podjęcia kilku istotnych decyzji architektonicznych. W tym wpisie pokazuję, jak na bazie usług AWS zbudować bardzo szybki RAG na potrzeby PoC
TL;DR
- Co: szybki RAG chatbot na AWS (Bedrock Knowledge Bases + S3 Vectors) pod PoC.
- Jak: pliki → S3 → Knowledge Bases (chunking + embeddingi) → S3 Vectors → chatbot.
- Dlaczego: minimum konfiguracji, szybkie demo na realnych danych.
- Co dostajesz: architekturę, kod, skrypty i konkretne pułapki z praktyki.
- Uwaga: to nie produkcja — brak guardrails, filtrów, multi-tenantów i pełnej kontroli.
Czym jest Amazon Bedrock Knowledge Bases?
Podstawą naszego systemu RAG (Retrieval Augmented Generation) będzie usługa Knowledge Bases z AWS Bedrock. Pozwala ona bardzo szybko zbudować system typu RAG, przetwarzając pliki wejściowe na bazę wektorową. Zaleta to łatwość konfiguracji i wiele integracji. Jako dane wejściowe możemy podawać tekst (txt, md, html, doc, csv, xls, pdf) oraz obrazki (.jpeg, .png) z:
- S3 (wspiera obrazki)
- Confluence
- Microsoft SharePoint
- Salesforce
- Web Crawler
- własny
Po przetworzeniu plików na wektory można je zapisać w:
- OpenSearch
- S3 Vectors
- Amazon Aurora
- Neptune
- Pinecone
- Redis Enterprise Cloud
- MongoDB Atlas
Wszystko to, plus możliwość wyboru konkretnych modeli i sposobu budowania embeddingów, daje usługę, którą można wykorzystać w niektórych przypadkach.
Budowa szybkiego RAG’a na AWS
Knowledge Bases można użyć do bardzo szybkiego zbudowania Chatbota RAG pod PoC. Mając gotowe klocki, jesteśmy w stanie zbudować taki system podczas rozmowy z klientem i pokazać działanie na żywo.
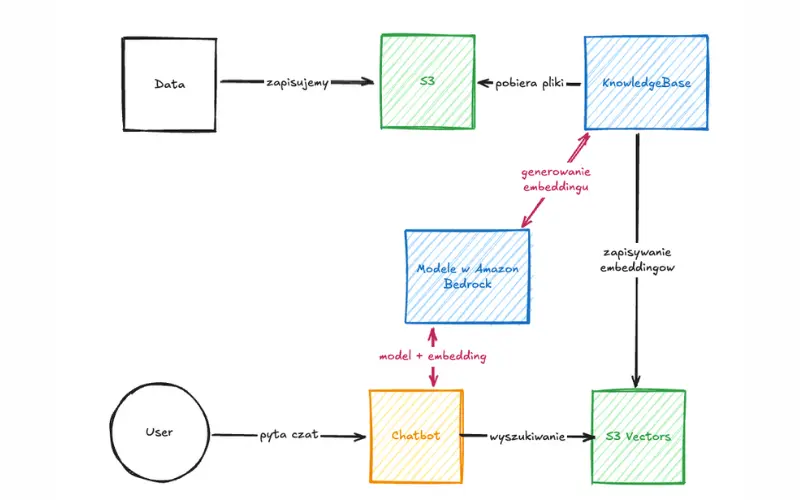
Są trzy główne elementy takiego systemu:
- proces przetwarzania danych
- chatbot
- proces odpytywania o dane
Kompletny przykład znajdziesz na GitHubie wraz z instrukcją, jak szybko to uruchomić.
Utworzenie S3, S3 Vectors i Knowledge Bases
Całość rozwiązania opiera się na trzech rzeczach:
- S3 - źródło danych, skąd bierzemy pliki do przetworzenia
- S3 Vectors - przechowywanie embeddingów oraz źródło wiedzy dla chatu
- Knowledge Bases - jako element przetwarzający pliki źródłowe do postaci wektorów.
Dzięki wykorzystaniu Knowledge Bases nie musimy się przejmować, jak przetwarzać pliki i dzielić je na mniejsze części, bo wszystko dzieje się automatycznie. Dla PoC i konkretnych use-case’ów ma to sens, ale zazwyczaj w produkcyjnych zastosowaniach chcemy mieć więcej kontroli.
Proces wygląda następująco:
- tworzymy S3 bucket
- tworzymy S3 Vectors index
- tworzymy indeks na S3
- tworzymy instancję Knowledge Bases
- tworzymy Data Source
Cały proces jest zautomatyzowany w repozytorium <Link do skryptu z GitHub>. Jeśli chcesz to zrobić po swojemu, warto zwrócić uwagę na kilka rzeczy:
filterableMetadataKeys vs nonFilterableMetadataKeys
1 const command = new CreateIndexCommand({
2 vectorBucketArn: vectorBucketArn,
3 indexName: indexName,
4 dimension: 1024, // Titan Embed Text v2 dimension
5 distanceMetric: DistanceMetric.COSINE,
6 dataType: "float32",
7 metadataConfiguration: {
8 nonFilterableMetadataKeys: ['AMAZON_BEDROCK_TEXT', 'AMAZON_BEDROCK_METADATA'],
9 },
10 });
11Bardzo istotne jest dodanie nonFilterableMetadataKeys dla wartości tworzonych przez Bedrock, bo inaczej Amazon Bedrock wywali się przy próbie uploadu embeddingów. Jest to związane z ograniczeniami nałożonymi na wektory:
- Filterable metadata per vector: do 2 KB
- Total metadata per vector: do 40 KB (filterable + non-filterable)
Rola dla Knowledge Bases
Tworząc nową instancję Knowledge Bases, trzeba pamiętać o odpowiednich uprawnieniach. Knowledge Bases potrzebuje:
- read dla S3, by pobrać pliki
- read, write dla S3 Vectors, by móc zapisać wektory oraz odczytać, jeśli chcesz testować
- możliwość korzystania z modeli Amazon Bedrock do tworzenia embeddingów i odpytywania w chacie
Oczekiwanie na Knowledge Bases
Zanim można utworzyć Data Source i wrzucić pliki, instancja Knowledge Bases musi być aktywna. Czyli trzeba poczekać :D Gdy robimy S3, mamy funkcję waitUntilBucketExists, której nie ma dla KB. Dlatego trzeba napisać własną funkcję, która co jakiś czas odpyta o status.
Strategia budowania embeddingów
Najważniejszym elementem konfiguracji Knowledge Bases jest strategia budowania wektorów. Brzmi tajemniczo, ale chodzi głównie o strategię chunkowania, czyli dzielenia większego tekstu na mniejsze fragmenty. Amazon daje kilka opcji, które mają swoje plusy i minusy. Najprostsza (która teraz jest skonfigurowana w skrypcie) to FIXED_SIZE, czyli dzielimy tekst na stałe fragmenty. To konfiguruje się dopiero na etapie budowania Data Source.
Wrzucenie danych
Gdy mamy stworzony Data Source (możemy to zrobić manualnie albo przez skrypt), możemy wrzucić dane. Proces wygląda następująco:
- wrzucenie danych do S3 (tego źródłowego)
- uruchomienie procesu (to jest mega istotne, bo nie robi się to automatycznie)
Za każdym razem, gdy wrzucisz nowy plik, musisz pamiętać o uruchomieniu procesu (StartIngestionJobCommand).
Budowa chatbota
Jest wiele narzędzi, które pozwalają budować chat. Ja osobiście korzystam z AI SDK od Vercel i bardzo polecam, bo:
- dostajemy lekki framework do budowania systemów agentowych
- gotowe hooki dla React’a do komunikacji z backendem
- gotowe elementy do budowania UI
Dzięki temu cały kod odpowiedzialny za część UI można napisać bardzo szybko i mieć gotową aplikację. To daje czas, by skupić się na istotnych elementach. Jeśli interesujesz się kodem, polecam zerknąć do repozytorium.
Odpytywanie S3 Vectors z embedding
Najważniejszym elementem całej aplikacji jest odpytywanie o informacje z naszej zbudowanej bazy wektorowej. Proces zawsze wygląda tak samo:
- zmiana pytania na postać embeddingu (istotne, by użyć tego samego modelu)
- odnalezienie treści podobnych w bazie wektorowej
- dorzucenie znalezionego tekstu do modelu
Jak to wygląda w kodzie
Wykorzystuję tutaj SDK od AWS, by wygenerować embedding i wyszukać podobne dokumenty. Warto zwrócić uwagę na:
- topK - ile embeddingów chcemy uzyskać
- returnMetadata - bardzo istotne, bo Knowledge Bases w metadanych wrzuca treść, która została zwektoryzowana
- result.metadata?.AMAZON_BEDROCK_TEXT - pod tym kluczem znajdziemy treść, którą musimy wrzucić do głównego modelu
1async function findRelevantContent(question: string): Promise<string> {
2 const indexArn = process.env.S3_VECTORS_INDEX_ARN;
3
4 if (!indexArn) {
5 console.warn("S3 Vectors configuration missing, skipping RAG");
6 return "";
7 }
8
9 try {
10 // Generate embedding for the query
11 const queryEmbedding = await generateEmbedding(question);
12
13 // Query S3 Vectors for similar documents
14 const queryCommand = new QueryCommand({
15 indexArn: indexArn,
16 queryVector: {
17 float32: queryEmbedding,
18 },
19 topK: 5, // Number of results to retrieve
20 returnMetadata: true,
21 returnDistance: true,
22 });
23
24 const queryResponse = await s3VectorsClient.send(queryCommand);
25 const results = queryResponse.vectors || [];
26
27 const content = results.map(result => result.metadata?.AMAZON_BEDROCK_TEXT || "").join("\n\n---\n\n");
28
29 return content;
30 } catch (error) {
31 console.error("Error retrieving context from S3 Vectors:", error);
32 return "";
33 }
34}
35Najważniejsza część kodu po stronie backendowej to generowanie odpowiedzi. Warto zwrócić uwagę na:
- do pobierania danych stworzyłem dedykowane narzędzie do pobierania informacji. Ważne, by dać w prompcie systemowym informacje, by z niego korzystał
- stopWhen: stepCountIs(5) -> bardzo ważne, by to ustawić, bo domyślnie AI SDK wykonuje 1 krok, czyli np. wywoła narzędzie, ale nie zwróci odpowiedzi.
1const result = streamText({
2 model: bedrock("eu.amazon.nova-2-lite-v1:0"),
3 messages: modelMessages,
4 system: `You are a helpful assistant. Check your knowledge base before answering any questions.
5 Only respond to questions using information from tool calls.
6 If no relevant information is found in the tool calls, respond, "Sorry, I don't know."`,
7 tools: {
8 getInformation: tool({
9 description: `Get information from your knowledge base to answer questions.`,
10 inputSchema: z.object({
11 question: z.string().describe('the users question'),
12 }),
13 execute: async ({ question }) => findRelevantContent(question),
14 }),
15 },
16 stopWhen: stepCountIs(5),
17 });
18Cały kod masz dostępny na GitHubie. Możesz wykorzystać go, by zbudować swoje własne rozwiązanie.
Kiedy stosować, a kiedy nie?
To nie jest konfiguracja, która zawsze się sprawdzi i jest gotowa na produkcję. To przykład, jak bardzo szybko można zbudować podstawowy RAG chatbot i przetestować ideę. By przekształcić to w system produkcyjny, warto zwrócić uwagę na kilka rzeczy:
- W chacie brakuje zabezpieczeń i można wrzucać dowolne pytania (również te zakazane). Wspominałem o tym w artykule o budowie chatbotów - potrzebne są Guardrails i analiza pytania od użytkownika, zanim zaczniemy odpowiadać.
- Konfiguracja serwisów przez SDK nie jest właściwym podejściem. Tutaj pozwala szybko coś zbudować, ale przy produkcyjnych zastosowaniach potrzebujemy większej kontroli nad tymi elementami. Warto przepisać to na stack CloudFormation albo Terraform.
- Aktualne wykorzystanie Knowledge Bases ogranicza nas w przypadku dużej zmienności danych, bo wszystko ląduje w jednym indeksie. Sprawdzi się to dla ogólnych źródeł (FAQ, helpline), ale nie gdy mamy różnych użytkowników.
- Brakuje opcji dodawania własnych filtrowanych metadanych w Knowledge Bases(np.: id usera), które podniosłyby jeszcze bardziej jakość wyszukiwania informacji.


