Testujesz, czy liczysz na szczęście? Ewaluacja modeli AI

Modele LLM są dla nas czarną skrzynką. Wrzucamy pytanie i liczymy na dobrą odpowiedź. Takie podejście powoduje wiele problemów przy próbie aktualizacji modeli, promptów czy zmianie założeń. Ale da się to robić lepiej dzięki ewaluacji modeli AI.
Po co testy modeli AI?
Nietrudno zauważyć, że co miesiąc mamy jakąś nowość związaną z AI - nowy model, ulepszenie starego, techniki promptowania, biblioteki itd. Najczęściej nowe modele są szybsze, lepsze i tańsze niż poprzednik. Ale jaką masz pewność, że aplikacja, która działała dobrze na starym modelu, będzie ciągle działać na nowym? Czy jesteś w stanie szybko określić, który model jest lepszy do twojego przypadku? Czy potrafisz powiedzieć, czy zmiany w prompcie nie spowodują regresji? Czy dołożenie nowych warunków nie zepsuje starych? I ile czasu potrzebujesz, by zmienić model?
Jeśli nie masz testów, to odpowiedź na takie pytanie będzie zgadywaniem i pewnie nie będzie super dokładna.
A co z oficjalnymi benchmarkami?
Oficjalne benchmarki są fajne do początkowej analizy modeli i porównywania ich między sobą. Ale nie dają żadnej wartości w kontekście twojej aplikacji (chyba, że twoja aplikacja ma rozwiązywać te same testy, co w oficjalnych benchmarkach).
U mnie ostatnio dużym zaskoczeniem były wyniki testów dla prompta context-check. W wynikach wyszło mi, że Amazon Nova Micro miała dokładnie ten sam poziom dokładności co Anthropic Claude 3.5 Sonnet, pomimo tego, że w oficjalnych rankingach jest dużo słabsza.
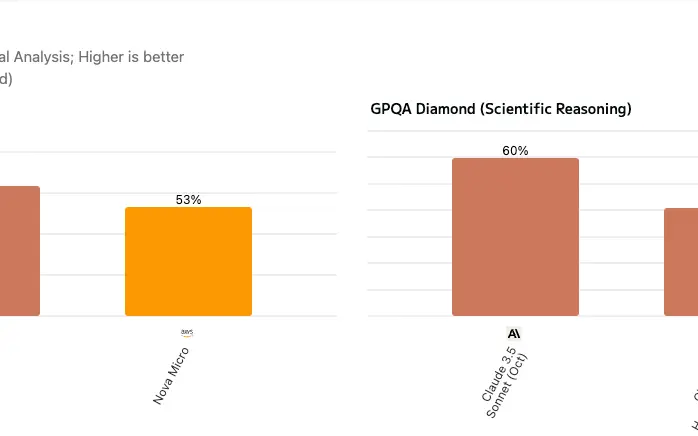
Dzięki temu, że mogłem szybko przetestować różne modele, to znalazłem model, który kosztuje mnie 100x mniej i jest dużo szybszy. Bez straty jakości.
Rodzaje ewaluacji modeli AI
Pomimo tego, że mało się mówi o ewaluacji modeli, to mamy kilka rodzajów testów, które warto wziąć pod uwagę.
Oficjalne benchmarki
Już wspomniane oficjalne benchmarki ogólnej „inteligencji” modeli pozwalają je porównywać między sobą. Jednak nie dają to żadnych informacji na temat tego, jak model będzie się zachowywał w konkretnych sytuacjach biznesowych. Warto je brać pod uwagę, ale jako wstęp do rozmowy czy ogólnej oceny możliwości modelu, a nie jako ostateczny wyznacznik.
Ewaluacja manualna
Ewaluacja przez człowieka (human evaluation) jest najprostszym sposobem na testy modeli AI. W tym podejściu to człowiek ocenia jakość odpowiedzi AI. Jest to dosyć czasochłonne i nie sprawdza się w każdym przypadku. Fajnie można to wykorzystać w podejściu human-in-the-loop, gdzie człowiek ocenia to, co stworzyło AI i zostawia opinię. Sprawdza się też w przypadku, gdy korzystamy z Claude/ChatGPT/innych i na bieżąco sprawdzamy, co stworzyło AI.
Ewaluacja automatyczna
Coś, na czym nam najbardziej zależy, czyli zestaw testów, które będą oceniały, czy to, co stworzyło AI, jest prawidłową odpowiedzią. Jest to też najbardziej skomplikowana opcja, bo w zależności od tego, co robi AI, możemy użyć innych metryk.
Monitoring
Po wdrożeniu AI warto też postawić monitoring, który będzie na bieżąco sprawdzał, co się dzieje w systemie i pomagał w rozwiązywaniu błędów oraz tworzeniu nowych testów pod automatyczne ewaluacje.
Testy penetracyjne
Poza sprawdzaniem, czy model działa poprawnie, warto sprawdzić, czy mamy zabezpieczenia przed tzw. prompt-injection, które mogą spowodować różne problemy w systemie i doprowadzić do wycieku danych. Tego typu testy to domena red teamu, który sprawdza, czy modele zostały wdrożone bezpiecznie.
Jak się przygotować do testów modeli AI
Automatyczna ewaluacja modeli nie jest prosta i warto się do niej odpowiednio przygotować. Poniżej znajdziesz opis procesu, który sam stosuję.
1. Ustal, co chcesz przetestować
Zanim siądziesz do pisania testów, warto się zastanowić, co chcesz testować, dla jakich modeli, w jakim języku, jakie są ograniczenia czasowe itd. Im więcej masz informacji, tym lepiej dla testów, które muszą być jak najbliżej danych produkcyjnych.
2. Przygotuj zestawy testowe
KLUCZOWY ETAP. Bez tego bardzo ciężko będzie zbudować dobre testy. Idealnie, to mieć przykładowe dokumenty/dane z produkcji, ale wiem, że nie zawsze to jest możliwe. Warto zebrać różnorodne dokumenty (np. różnie wygenerowane faktury) i wspomóc się danymi wygenerowanymi syntetycznie.
3. Wybierz metryki
W zależności od tego, co testujesz, będziesz potrzebował innych metryk, np.:
- Kategoryzacja - accuracy
- YES/NO - accuracy, recall, F1
- Wyciąganie danych z dokumentów - accuracy, testy struktury, podobieństwo danych
- Generowanie odpowiedzi - ton odpowiedzi, użycie kontekstu, test na halucynacje
Oczywiście to są tylko przykłady i warto dobrać te metryki, na których zależy ci w końcowym produkcie. Nowe metryki zawsze można dołożyć później i przetestować jeszcze raz model.
4. Wybierz początkowe modele
Wybierz początkowe modele do testów. Ja najczęściej zaczynam od bardziej zaawansowanych modeli, a potem stopniowo wybieram mniejsze i optymalizuję prompt. Jeśli masz konkretne modele, z których musisz korzystać, to zacznij od nich. Warto też wykorzystać LLM Gateway, by móc się łatwiej przełączać między różnymi modelami.
Testowanie modeli z promptfoo
Jeśli chodzi o narzędzia do testów LLM, to jest parę opcji na rynku, np.:
- https://github.com/openai/evals
- https://github.com/confident-ai/deepeval
- https://github.com/promptfoo/promptfoo
Ja od jakiegoś czasu korzystam z promptfoo i jestem bardzo zadowolony. Przede wszystkim daje dużo elastyczności i można wykorzystywać zarówno jako CLI z plikiem yaml, jak i wywołując w kodzie jako zależność npm. Dzięki temu można szybko testować modele, jak i budować bardziej zaawansowane procesy. Ja aktualnie w jednym projekcie na bazie promptfoo buduję pipeline do testów z wykresami w Metabase.
Najprościej jest zacząć jako narzędzie w CLI:
1prompts:
2 - |-
3 You are Customer Service guard.
4 Your task is to decide if the customer service should respond to customer query or not.
5 You will be given a customer query.
6 You will respond with "1" if the response is appropriate and "0" if it is not.
7
8 <CRITERIA>
9 Customer Query: question about order status, shipping, returns, product information, account issues.
10 Response: "1"
11
12 Customer Query: personal questions, philosophical questions, inappropriate content, or anything unrelated to customer service
13 Response: "0"
14 </CRITERIA>
15
16 Response only "0" or "1", without any additional text or thoughts
17
18 Customer Query: {{query}}
19 Answer:
20providers:
21 - ollama:completion:gemma3:12b
22tests:
23 - vars:
24 query: "I want to know the status of my order #12345."
25 assert:
26 - type: javascript
27 value: "output.trim() === '1'"
28 - vars:
29 query: "What is the meaning of life?"
30 assert:
31 - type: javascript
32 value: "output.trim() === '0'"
33Potem wystarczy to uruchomić poleceniem
1promptfoo eval
2Struktura jest dosyć oczywista, ale warto wspomnieć o kilku możliwościach.
prompts
Tutaj nie ma co się rozpisywać. Podajemy prompty, które chcemy przetestować. Może być ich więcej niż 1. Możemy przekazywać tam używać zmiennych z sekcji vars przy pomocy {{nazwa_zmiennej}} (w przykładzie korzystam z zmiennej query). Oprócz przekazywania promptu bezpośrednio w pliku, można też dać odwołanie do pliku z promptem (będzie to wygodniejsze dla dłuższych promptów).
1prompts:
2 - file://simple_prompt.txt
3 - file://advanced_prompt.txt
4providers
Promptfoo ma bogatą listę dostępnych providerów, których nie będę wymieniać. Po szczegóły odsyłam do spisu. Ja osobiście polecam LiteLLM i samemu zarządzać modelami. Każdy model ma opisane możliwości konfiguracji i wymagane zmienne środowiskowe, by wszystko uruchomić.
tests
Sekcja, w której się najwięcej dzieje. To tutaj definiuje się testy, na które składają się zmienne i asercje. Można to zrobić tak, jak w przykładowym pliku powyżej, lub przygotować odpowiednie pliki CSV.
1query, result
2"I want to know the status of my order #12345.", 1
3"What is the meaning of life?", 0
4I wtedy konfiguracja testów wygląda następująco:
1defaultTest:
2 assert:
3 - type: javascript
4 value: "output.trim() === context.vars.result.trim()"
5tests:
6 - file://context.csv
7Dochodzi sekcja defaultTest, która zawiera asercje, które będą uruchomione dla każdego testu. Wykorzystujemy tutaj jedną z zmiennych w kontekście jako oczekiwany rezultat i na bazie tego budujemy test. Jest to dużo wygodniejsze niż trzymanie wszystkiego w jednym pliku i ułatwia zarządzanie.
Wskazówka do testów. Wykorzystaj promptfoo eval --verbose, by sprawdzić, co zwracają modele LLM.Jeszcze słówko na temat asercji. W moich przykładach korzystałem z kodu JavaScript, który pozwala na elastyczne tworzenie różnego rodzaju testów. I jest to też sposób na tworzenie różnych metryk, np. F1. Ale oprócz tego jest cała gama różnych metryk gotowych do użycia:
- proste (np. equals, contains, is-json, contains-json itd.)
- metryki deterministyczne (np. levenshtein, rouge-n, similar, BLEU, GLEU itd.)
- metryki oparte o modele (np. g-eval, context-faithfulness, answer-relevance)
Zawsze warto wybierać te, które pozwolą odpowiedzieć ci na pytanie: Czy ten model i ten prompt są ok.
Podsumowanie
- Jeśli myślisz na poważnie o budowaniu aplikacji korzystających z modeli LLM, to zadbaj o testy.
- Zanim zaczniesz testować, warto się przygotować: pomyśleć, co się chce testować, jakie metryki nas interesują i z jakimi modelami chcemy zacząć.
- Dane są najważniejsze - im lepsze dane testowe, tym lepsze wyniki końcowe.
- Polecam pobawić się promptfoo, bo daje naprawdę sporo możliwości testowania modeli.


